Abstract
Large vision–language models (VLMs) excel at multimodal understanding but fall short when extended to embodied tasks, where instructions must be transformed into low-level motor actions. We introduce SP-VLA, a dual-system Vision–Language–Action framework that leverages Spatial Priors as a bridge between linguistic instructions and embodiment-specific control. SP-VLA aligns action learning with spatial priors through two stages: (i) spatial grounding pre-training, which equips the VLM with transferable priors via scalable point, box, and trajectory prediction from both web-scale and robot-specific data, and (ii) spatially guided action post-training, which encourages the model to produce richer spatial priors to guide action generation via spatial prompting. This design preserves spatial grounding during policy learning and promotes consistent optimization across spatial and action objectives. Empirically, SP-VLA achieves substantial improvements over vanilla VLA, with performance increasing from 66.1 to 84.6 on Google Robot and from 54.7 to 73.2 on WidowX, establishing new state-of-the-art results on SimplerEnv. It also demonstrates stronger generalization to unseen objects and paraphrased instructions, as well as robustness to long-horizon perturbations in real-world settings. These results highlight scalable spatially guided training as a promising direction for robust, generalizable robot learning. We will release code, data, and model checkpoints to support future research.
Model Overview
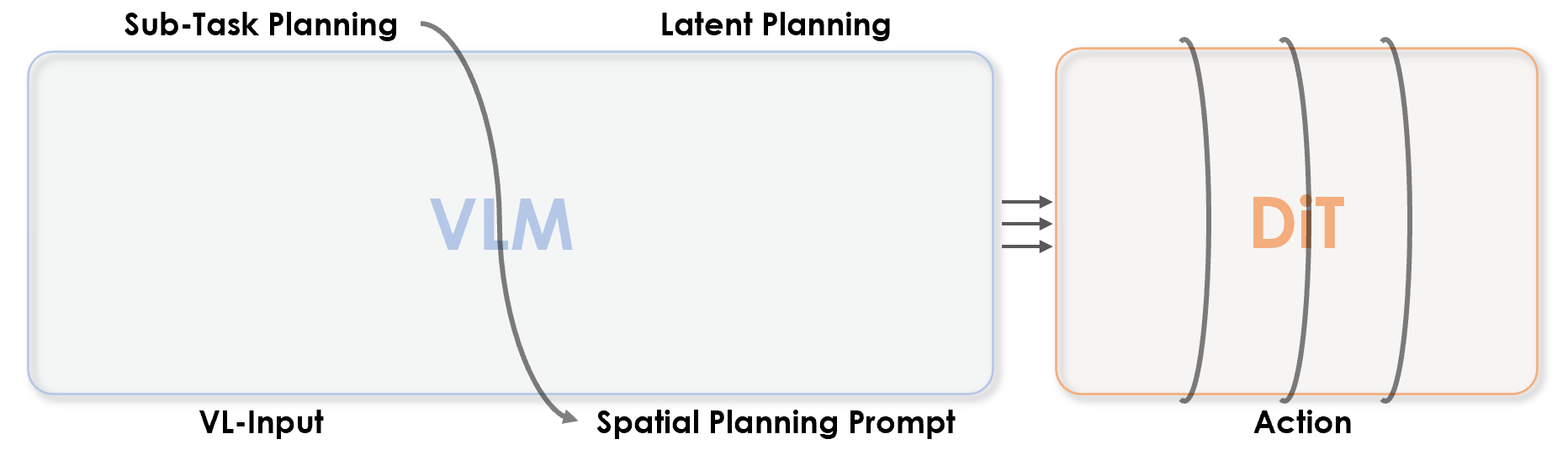
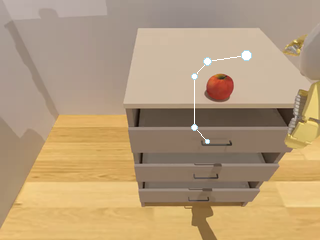
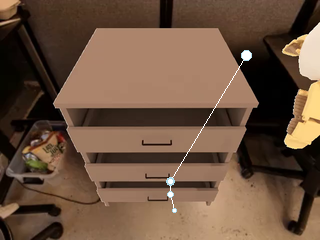
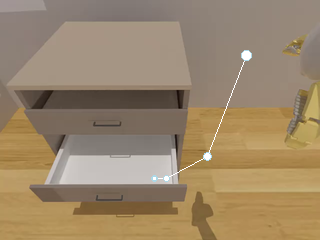
SP-VLA integrates spatial grounding into the vision–language–action training pipeline. Given a task instruction, the VLM planner produces latent plans through explicit spatial prompting, which then effectively guides the action expert to generate control signals.
Results
Watch SP-VLA perform instruction-following manipulation tasks in both large-scale simulated environments and real-world tasks.